简介
CNN -> Convolutional Neural Network
卷积神经网络是由一个或多个卷积层和顶端的全连通层(也可以使用1x1的卷积层作为最终的输出)组成的一种前馈神经网络
基本概念
局部感受野(Local Receptive Fields)
一般的神经网络往往会把图像的每一个像素点连接到全连接的每一个神经元中,而卷积神经网络则是把每一个隐藏节点只连接到图像的某个局部区域,从而减少参数训练的数量。
例如,一张1024×720的图像,使用9×9的感受野,则只需要81个权值参数。对于一般的视觉也是如此,当观看一张图像时,更多的时候关注的是局部。
共享权值(Shared Weights)
在卷积神经网络的卷积层中,神经元对应的权值是相同的,由于权值相同,因此可以减少训练的参数量。共享的权值和偏置也被称作卷积核或滤波器
池化(Pooling)
由于待处理的图像往往都较大,而实际处理时没必要直接对原图进行分析,最主要的是要能够有效获得图像的特征。因此可以采用类似图像压缩的思想,对图像进行卷积之后,通过一个下采样过程来调整图像的大小
结构组成
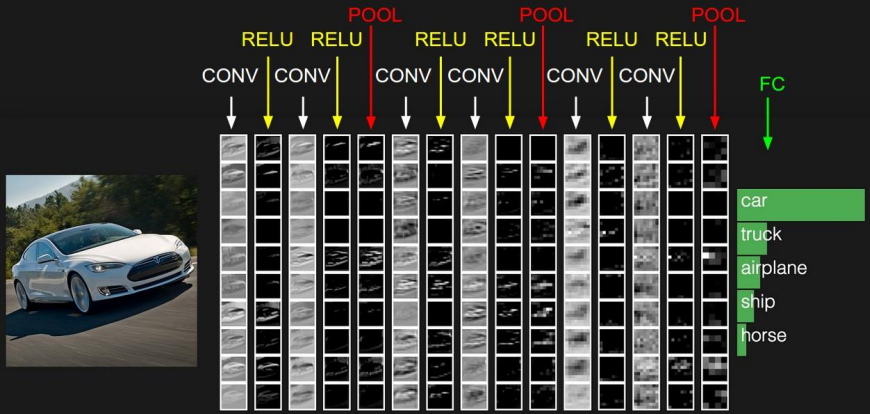
我们通过卷积的计算操作来提取图像局部的特征,每一层都会计算出一些局部特征,这些局部特征再汇总到下一层,这样一层一层的传递下去,特征由小变大,最后在通过这些局部的特征对图片进行处理,这样大大提高了计算效率,也提高了准确度。
卷积层
提取特征
卷积计算
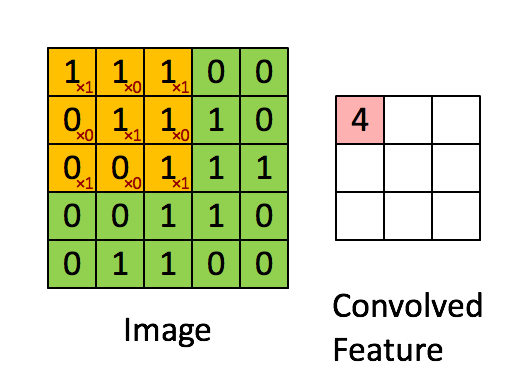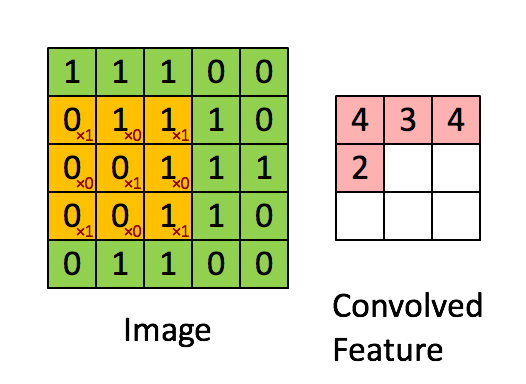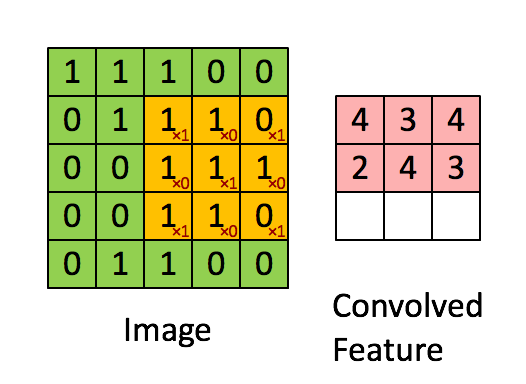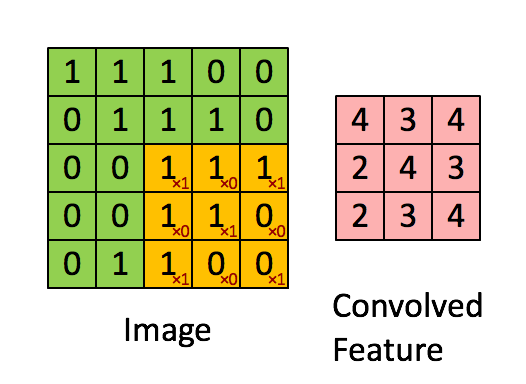
动图来源于:stanford.edu, Feature extraction using convolution
NOTE: 深度学习中的卷积与信号处理中的卷积略有不同,深度学习中的卷积略去了翻转的步骤(因为起初卷积核是随机生成的,没有方向)
- 输入矩阵大小 n
- 卷积核大小 f
- 边界填充 (p)adding,指在原矩阵周围填充的层数
- 步长 (s)tride
计算公式
卷积结果大小:(n - f + 2p) / s + 1向下取整
多个卷积核
在每一个卷积层我们会设置多个卷积核,代表多个不同的特征,这些特征就是需要传递到下一层的输出,训练的过程就是训练不同的核
激活函数
引入非线性关系
由于卷积的操作是线性的,所以需要使用进行激活,通常使用Relu
池化层
减少参数数量
通过减少卷积层之间的连接,降低运算复杂程度。
池化层一般放在卷积层后面,所以池化层池化的是卷积层的输出
一般使用的有最大池化max-pooling和平均池化mean-pooling
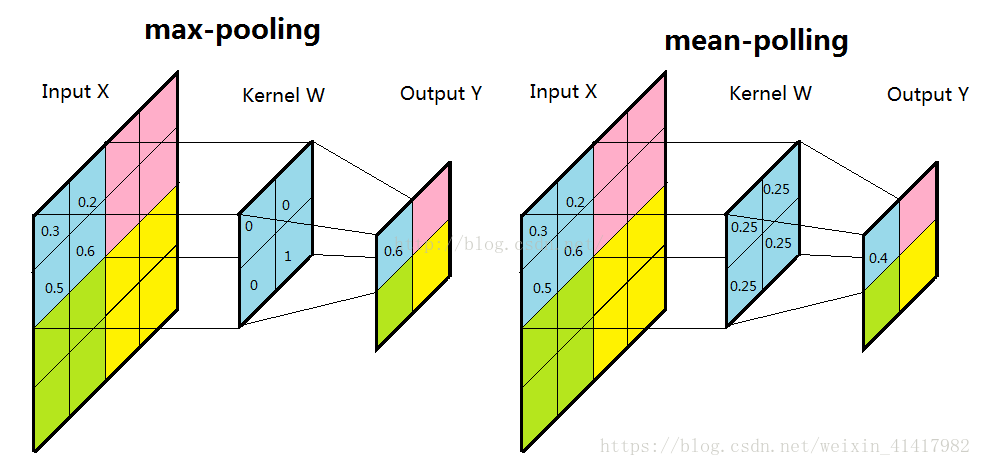
操作与卷积类似,即过滤器在矩阵上滑动
dropout层
dropout是2014年 Hinton 提出防止过拟合而采用的trick,增强了模型的泛化能力 Dropout(随机失活)是指在深度学习网络的训练过程中,按照一定的概率将一部分神经网络单元暂时从网络中丢弃,相当于从原始的网络中找到一个更瘦的网络,说的通俗一点,就是随机将一部分网络的传播掐断,听起来好像不靠谱,但是通过实际测试效果非常好。
全连接层
一般作为最后的输出层使用
我们的特征都是使用矩阵表示的,所以再传入全连接层之前还需要对特征进行压扁,将他这些特征变成一维的向量,如果要进行分类的话,就是用sofmax作为输出,如果要是回归的话就直接使用linear即可
经典模型
LeNet-5
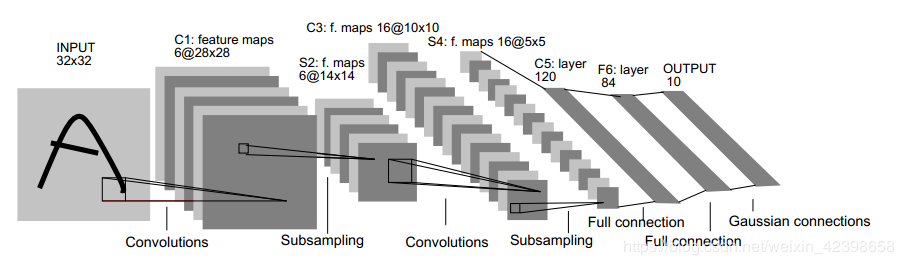
- 用卷积提取空间特征;
- 由空间平均得到子样本;
- 用 tanh 或 sigmoid 得到非线性;
- 用 multi-layer neural network(MLP)作为最终分类器;
- 层层之间用稀疏的连接矩阵,以避免大的计算成本。
示例可见->Pytorch官方教程_训练一个分类器
详细解析->深度学习 — 卷积神经网络CNN(LeNet-5网络详解)
AlexNet
论文:《ImageNet Classification with Deep Convolutional Neural Networks》
可以看作LeNet的更深更广的版本,可用于学习更复杂的对象,更丰富更高维的图像特征。AlexNet的特点:
- 更深的网络结构
- 用ReLu替换之前的Sigmoid作为激活函数
- 使用Dropout抑制过拟合
- 使用数据增强Data Augmentation抑制过拟合
- 使用层叠的卷积层,即卷积层+卷积层+池化层来提取图像的特征
- 重叠最大池,避免平均池的平均效果;
- 使用 GPU NVIDIA GTX 580 可以减少训练时间,这比用CPU处理快了 10 倍,所以可以被用于更大的数据集和图像上。
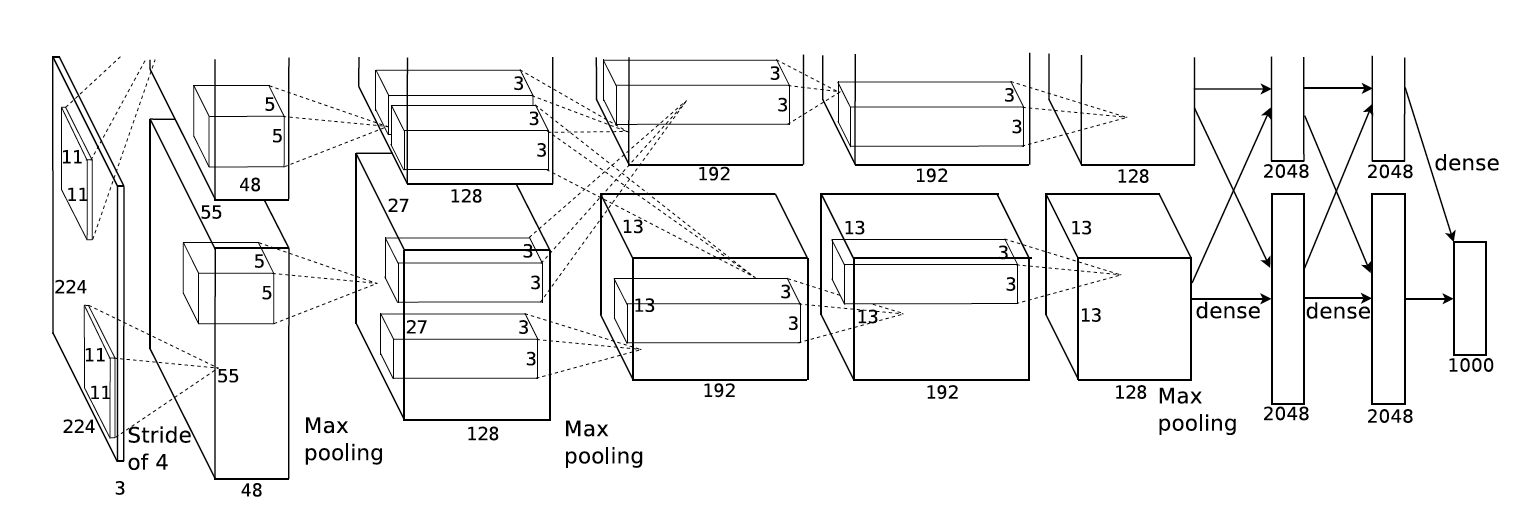
图中分为上下两个部分的网络,论文中提到这两部分网络分别对应两个GPU,只有到了特定的网络层后才需要两块GPU进行交互,这种设置完全是利用两块GPU来提高运算的效率,其实在网络结构上差异不是很大
在这里稍微简化,看作只有一个部分。AlexNet有8层,5层卷积,3层全连接层。
AlexNet有一个特殊的计算层:LRN(Local Response Normalized层),这一层用于对当前层的输出结果做平滑处理
Alexnet的每一阶段(含一次卷积主要计算的算作一层)可以分为8层:
- 卷积层1
Conv-Relu-Pooling-LRN
输入为 224×224×3的图像,卷积核的数量为96,论文中两片GPU分别计算48个核
卷积核的大小为 11×11×3,stride = 4, padding = 0. 卷积后为 54x54,dimention = 96
池化,pool_size = (3, 3), stride = 2, padding = 0
最终获得第一层卷积的feature map,size为27x27x96
- 卷积层2
Conv-Relu-Pooling-LRN
输入为上一层卷积的feature map,卷积的个数为256个,论文中两片GPU分别有128个卷积核
卷积核大小:5x5x48,stride = 1, padding = 2
池化为max_pooling, pool_size = (3, 3), stride = 2
- 卷积层3
Conv-Relu
卷积核个数为384,大小3x3x256, padding = 1
- 卷积层4
Conv-Relu
卷积核个数为384,大小3x3, padding = 1
- 卷积层5
Conv-Relu-Pooling
卷积核个数为256,大小3x3, padding = 1
进行max_pooling, pool_size = (3, 3), stride = 2
- 全连接层1
fc-Relu-Dropout
Dropout层:在训练中以50%的概率使得隐藏层的某些neuron的输出为0,这样就都丢掉了一半节点的输出,BP的时候也不会更新这些节点,防止过拟合
-
全连接层2
fc-Relu-Dropout -
全连接层3
fc-softmax
三个全连接层每一层的神经元的个数为4096,最终输出softmax为1000,因为ImageNet这个比赛的分类个数为1000。全连接层中使用了RELU和Dropout。
Pytorch的torchvision包中包含AlexNet的官方实现
import torcvision
model = torchvision.models.alexnet(pretrained=False)
print(model)
'''
AlexNet(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(4): ReLU(inplace=True)
(5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU(inplace=True)
(8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU(inplace=True)
(10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(6, 6))
(classifier): Sequential(
(0): Dropout(p=0.5, inplace=False)
(1): Linear(in_features=9216, out_features=4096, bias=True)
(2): ReLU(inplace=True)
(3): Dropout(p=0.5, inplace=False)
(4): Linear(in_features=4096, out_features=4096, bias=True)
(5): ReLU(inplace=True)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
'''
VGG
论文:Very deep convolutional networks for large-scale image recognition
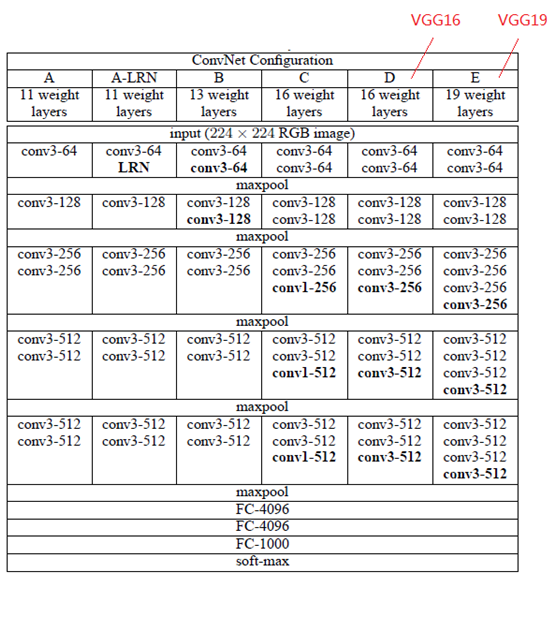
论文中提出了多个版本的VGG结构,其中D就是著名的VGG16
- 每个卷积层中使用更小的 3×3 filters,并将它们组合成卷积序列
- 多个3×3卷积序列可以模拟更大的接收场的效果
- 每次的图像像素缩小一倍,卷积核的数量增加一倍
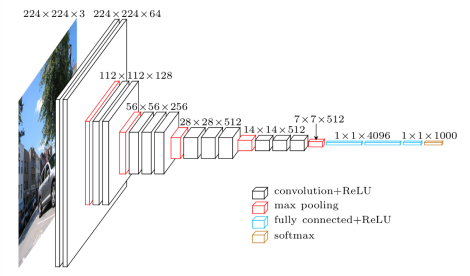
VGG由5层卷积层、3层全连接层、softmax输出层构成,层与层之间为max-pooling,所有隐层的激活函数均为ReLu
- 小卷积核
VGG采用多个小卷积核(3x3)的卷积层代替一个卷积核较大的卷积层。这样一方面可以减少卷积层的参数,另一方面相当于进行了更多的非线性映射,可以增加网络的拟合/表达能力
VGG的作者认为,当input为8x8,经过三层Conv 3x3后,output为2x2,这等同于1层Conv 7x7的结果;当input为8x8,经过2层Conv 3x3后,output为2x2,等同于1层Conv 5x5的结果。这样可以增加非线性映射,也能很好地减少参数
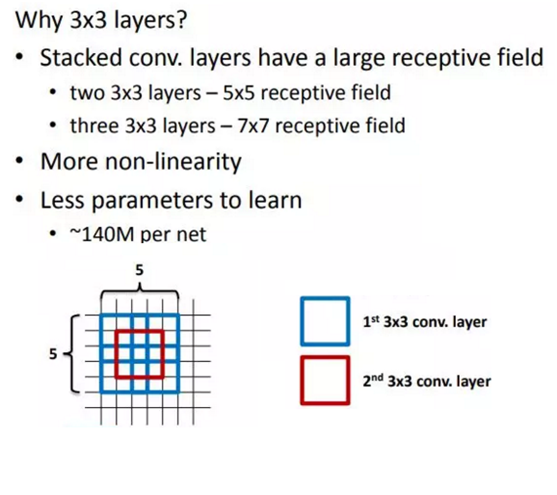
- 小池化核
相比于AlexNet的3x3的池化核, VGG全部采用2x2的池化核
- 通道数多
VGG网络第一层的通道数为64,后面每层都进行了翻倍,最多到512个通道,通道数的增加,使得更多的信息可以被提取出来
- 层数更深、特征图更宽
由于卷积核专注于扩大通道数、池化专注于缩小宽和高,使得模型架构上更深更宽的同时,控制了计算量的增加规模。
同样,torchvision包中有官方实现
import torchvision
model = torchvision.models.vgg16(pretrained=False)
print(model)
'''
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace)
(2): Dropout(p=0.5)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace)
(5): Dropout(p=0.5)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
'''
简化图如下:
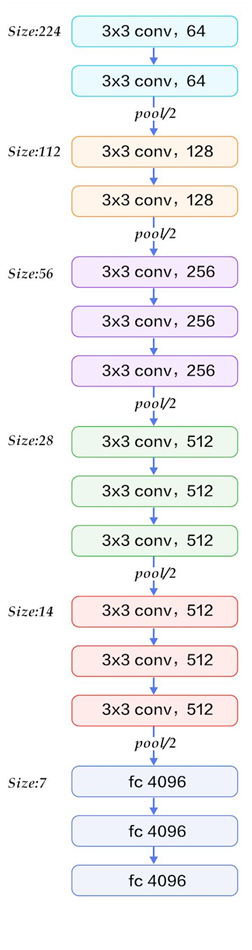
深度解析:大话CNN经典模型:VGGNet
GoogLeNet
论文:Rethinking the Inception Architecture for Computer Vision
GoogLeNet团队提出了Inception网络结构,就是构造一种“基础神经元”结构,来搭建一个稀疏性、高计算性能的网络结构。
Inception V1
通过设计一个稀疏网络结构,但是能够产生稠密的数据,既能增加神经网络的表现,又能保证计算资源的使用效率。谷歌题出了最原始的Inception的基本结构
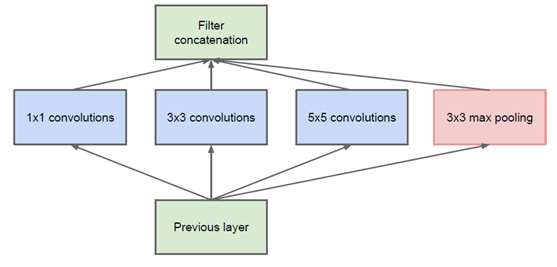
该结构将CNN中常用的卷积(1x1,3x3,5x5)、池化操作(3x3)堆叠在一起(卷积、池化后的尺寸相同,将通道相加),一方面增加了网络的宽度,另一方面也增加了网络对尺度的适应性。
网络中的卷积层能够提取输入的每一个细节信息,同时5x5的滤波器也能够覆盖大部分接受层的输入。还可以进行一个池化操作,以减少空间大小,降低过度拟合。在这些层之上,每个层后都要做一个ReLu操作,以增加网络的非线性特性
然而这个Inception原始版本,所有的卷积核都在上一层的所有输出上来做,而那个5x5的卷积核所需的计算量就太大了,造成了特征图的厚度很大,为了避免这种情况,在3x3前、5x5前、max pooling后分别加上了1x1的卷积核,以起到了降低特征图厚度的作用,这也就形成了Inception v1的网络结构,如下图所示:
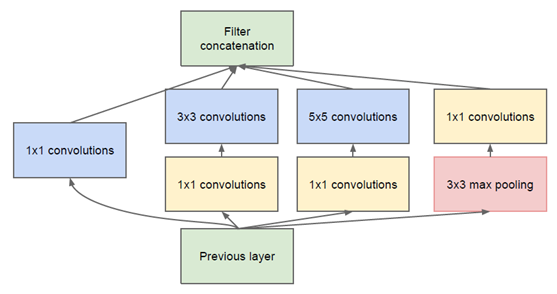
1x1卷积的主要目的是为了减少维度,还用于修正线性激活(ReLU)。
GoogLeNet
- 使用1x1的卷积块(NIN)来减少特征数量,这通常被称为“瓶颈”,可以减少深层神经网络的计算负担
- 每个池化层之前,增加feature maps, 增加每一层的宽度来增多特征的组合性
GoogLeNet最大的特点就是包含若干个Inception模块,所以有时候也称作 Inception Net。
GoogLeNet虽然层数要比VGG多很多,但是由于Inception的设计,计算速度方面要快很多。
网络结构如下(共22层):
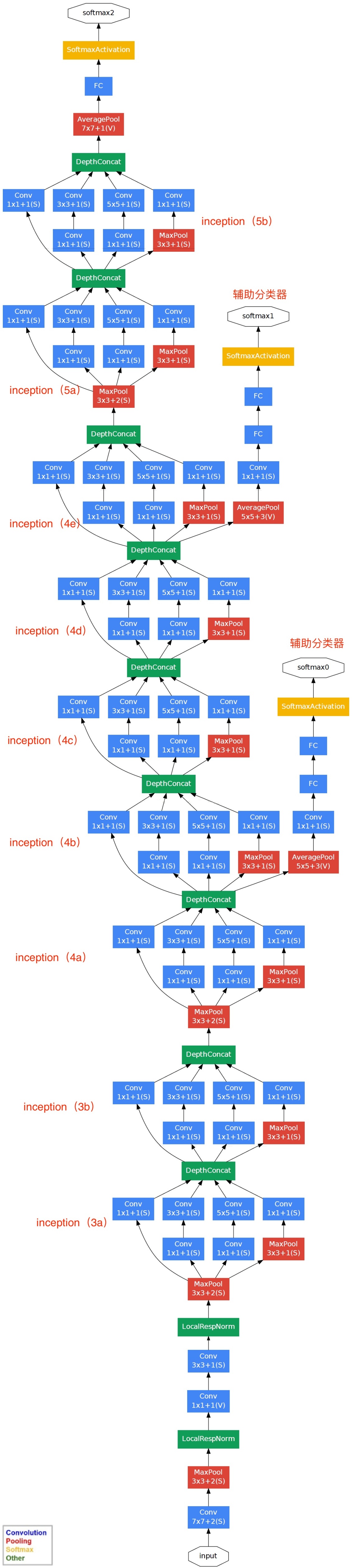
Inception架构的主要思想是找出如何让已有的稠密组件接近与覆盖卷积视觉网络中的最佳局部稀疏结构。
现在需要找出最优的局部构造,并且重复几次。之前的一篇文献提出一个层与层的结构,在最后一层进行相关性统计,将高相关性的聚集到一起。这些聚类构成下一层的单元,且与上一层单元连接。假设前面层的每个单元对应于输入图像的某些区域,这些单元被分为滤波器组。在接近输入层的低层中,相关单元集中在某些局部区域,最终得到在单个区域中的大量聚类,在最后一层通过1x1的卷积覆盖
上面的话听起来很生硬,其实解释起来很简单:每一模块我们都是用若干个不同的特征提取方式,例如 3x3卷积,5x5卷积,1x1的卷积,pooling等,都计算一下,最后再把这些结果通过Filter Concat来进行连接,找到这里面作用最大的。而网络里面包含了许多这样的模块,这样不用我们人为去判断哪个特征提取方式好,网络会自己解决(是不是有点像AUTO ML),在Pytorch中实现了InceptionA-E,还有InceptionAUX 模块。
# inception_v3需要scipy
import torchvision
model = torchvision.models.inception_v3(pretrained=False) #我们不下载预训练权重
print(model)
'''
太多了,这里就不贴了
'''
ResNet
刚才的googlenet已经很深了,ResNet可以做到更深,通过残差计算,可以训练超过1000层的网络,俗称跳连接
退化问题
网络层数增加,但是在训练集上的准确率却饱和甚至下降了。这个不能解释为overfitting,因为overfit应该表现为在训练集上表现更好才对。
这个就是网络退化的问题,退化问题说明了深度网络不能很简单地被很好地优化
残差网络的解决办法
深层网络的后面那些层是恒等映射,那么模型就退化为一个浅层网络。那现在要解决的就是学习恒等映射函数了。让一些层去拟合一个潜在的恒等映射函数H(x) = x比较困难。如果把网络设计为H(x) = F(x) + x。我们可以转换为学习一个残差函数F(x) = H(x) - x。 只要F(x)=0,就构成了一个恒等映射H(x) = x. 而且,拟合残差肯定更加容易。
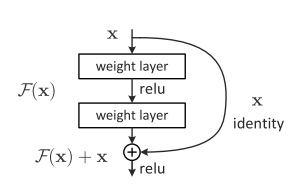
我们在激活函数前将上一层(或几层)的输出与本层计算的输出相加,将求和的结果输入到激活函数中做为本层的输出,引入残差后的映射对输出的变化更敏感,其实就是看本层相对前几层是否有大的变化,相当于是一个差分放大器的作用。
图中的曲线就是残差中的shoutcut,他将前一层的结果直接连接到了本层,也就是俗称的跳连接。
网络结构
以经典的resnet18来看一下网络结构
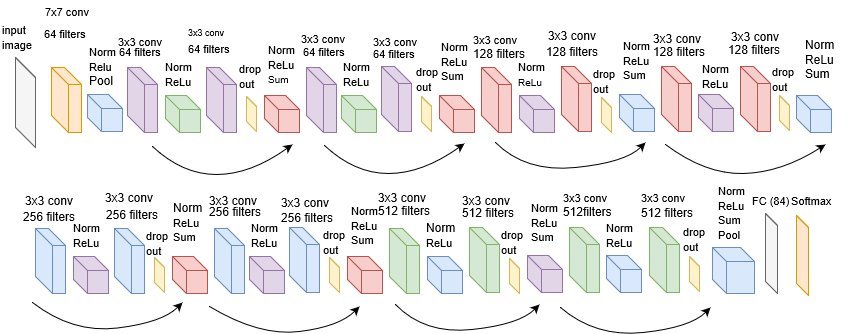
import torchvision
model = torchvision.models.resnet18(pretrained=False) #我们不下载预训练权重
print(model)
选择模型
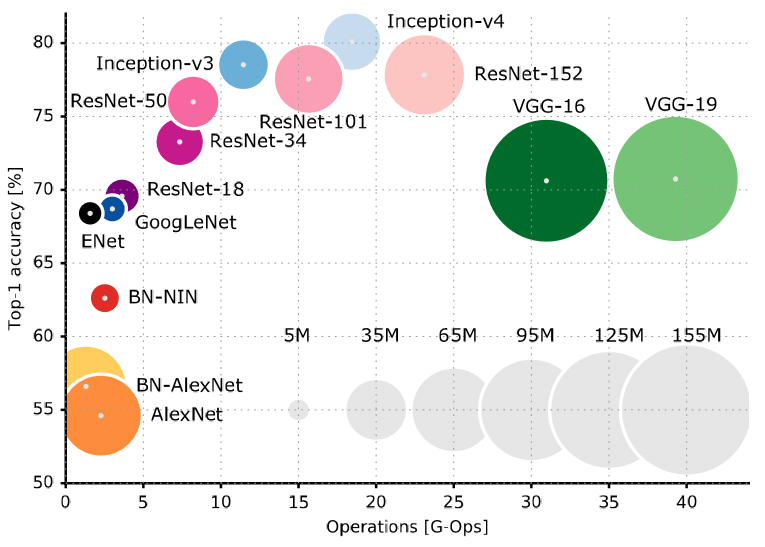
以上表格可以清楚的看到准确率和计算量之间的对比。
小型图片分类任务,resnet18基本上已经可以了,如果真对准确度要求比较高,再选其他更好的网络架构。