在我们在训练模型的过程中,一般会使用一些正则化方法来防止过拟合。
但是我们可能会正则化的程度太高或太小了,即我们在选择λ的值时也需要思考与之前选择多项式模型次数类似的问题。
我们选择一系列的想要测试的λ值,比如这里选择 0-10之间的值,通常呈现2倍关系(如:0,0.01,0.02,0.04,0.08,0.15,0.32,0.64,1.28,2.56,5.12,10 共12个)。
我们同样把数据分为训练集、交叉验证集和测试集。

选择λ的方法
-
使用训练集训练出12个不同程度正则化的模型
-
用12个模型分别对交叉验证集计算的出交叉验证误差
-
选择得出交叉验证误差最小的模型
-
运用步骤3中选出模型对测试集计算得出推广误差
我们也可以同时将训练集和交叉验证集模型的代价函数误差与λ的值绘制在一张图表上:
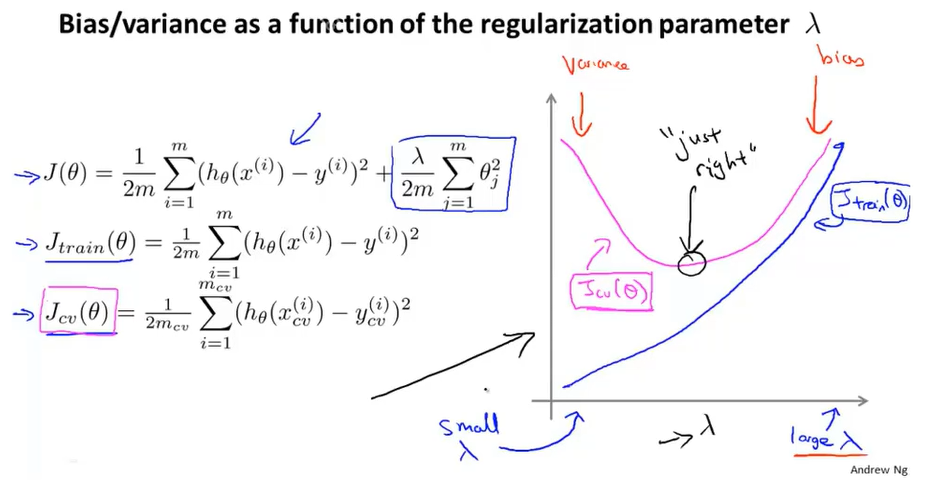
当
λ较小时,训练集误差较小(过拟合)而交叉验证集误差较大
随着
λ的增加,训练集误差不断增加(欠拟合),而交叉验证集误差则是先减小后增加