在PyTorch中使用Mini-batch这种方法进行训练
Mini-batch的梯度下降法
对整个训练集进行梯度下降法的时候,我们必须处理整个训练数据集,然后才能进行一步梯度下降,即每一步梯度下降法需要对整个训练集进行一次处理,如果训练数据集很大的时候处理速度会很慢,而且也不可能一次的载入到内存或者显存中
所以我们会把大数据集分成小数据集,一部分一部分的训练,这个训练子集即称为Mini-batch。
对于普通的梯度下降法,一个epoch只能进行一次梯度下降;而对于Mini-batch梯度下降法,一个epoch可以进行Mini-batch的个数次梯度下降。

普通的batch梯度下降法和Mini-batch梯度下降法代价函数的变化趋势,如下图所示:
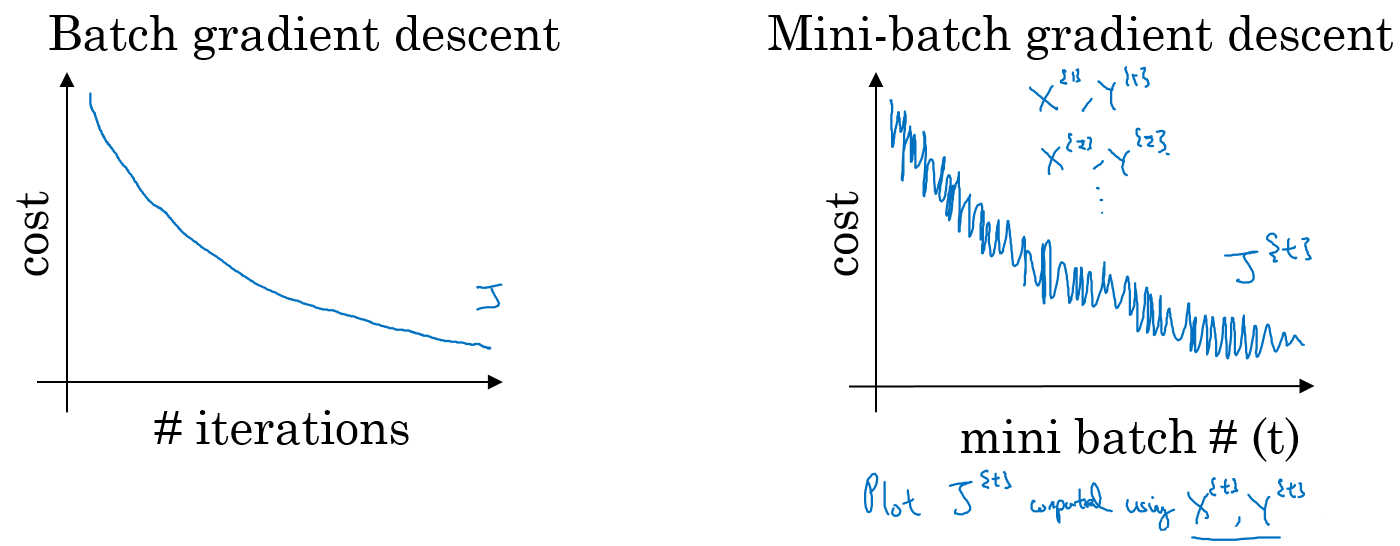
- 如果训练样本的大小比较小时,能够一次性的读取到内存中,那我们就不需要使用Mini-batch
- 如果训练样本的大小比较大时,一次读入不到内存或者现存中,那我们必须要使用 Mini-batch来分批的计算
- Mini-batch size的计算规则如下,在内存允许的最大情况下使用2的N次方个size

torch.optim
torch.optim是一个实现了各种优化算法的库。大部分常用优化算法都有实现
torch.optim.SGD
Stochastic Gradient Descent
随机梯度下降算法,带有动量(momentum)的算法作为一个可选参数可以进行设置
可以把动量看作惯性:当你跑起来,由于惯性的存在你跑起来会比刚起步加速的时候更轻松,当你跑过头,想调头往回跑,惯性会让你拖着你。 在普通的梯度下降法的方向相同,则会加速。反之,则会减速。 加了动量的优势:
- 加速收敛
- 提高精度(减少收敛过程中的振荡)
SGD(params, lr=<required parameter>, momentum=0, dampening=0, weight_decay=0, nesterov=False)
torch.optim.RMSprop
Root Mean Square Prop
均方根传递。也是一种可以加快梯度下降的算法,利用RMSprop算法,可以减小某些维度梯度更新波动较大的情况,使其梯度下降的速度变得更快
相较于gradient descent with momentum,RMSprop的思想是:
- 对于梯度震动较大的项,在下降时,减小其下降速度;
- 对于震动幅度小的项,在下降时,加速其下降速度。
torch.optim.Adam
Adam 优化算法的基本思想就是将 Momentum 和 RMSprop 结合起来形成的一种适用于不同深度学习结构的优化算法
它能基于训练数据迭代地更新神经网络权重
e.d.
# 这里的lr,betas,还有eps都是用默认值即可,所以Adam是一个使用起来最简单的优化方法
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-08)